Pediatric critical care is a dynamic, high-stakes process involving constant monitoring and adjustments in life-saving treatments. We frame clinical decision-making as imitation learning from observational data, in which actions are not directly observed. We find that the TabPFN-based approach consistently outperforms classical baselines, supporting its use as a strong clinician-behavior baseline for pediatric ECMO decision support.
Key challenges in pediatric ECMO
Building decision support systems for this domain is complicated by the incomplete and difficult-to-formalize nature of pediatric-specific protocols, alongside the ethical and practical impossibility of experimentation on critically ill children.
- Irregular time between actions. Clinical observations arrive at irregular intervals; we aggregate trajectories into hourly windows.
- Concurrent, high-dimensional action space. Several parameters can be changed simultaneously, without explicit annotations.
- No explicit intervention labels. Interventions are not explicitly timestamped in the raw dataset; we infer each action by monitoring its delta over a 1-hour window.
- Severe data scarcity. A large number of observations for a small number of patients, i.e., imbalance of the features vs examples.
- No explicit reward signal. One has to infer the success of a trajectory based on the patient outcome. Evaluating new strategies directly on live patients is ethically and practically unfeasible.
Imitation learning pipeline
Unlike standard reinforcement learning, which requires active environmental interaction, offline imitation learning allows us to exploit expert demonstrations already present in historical clinical records.
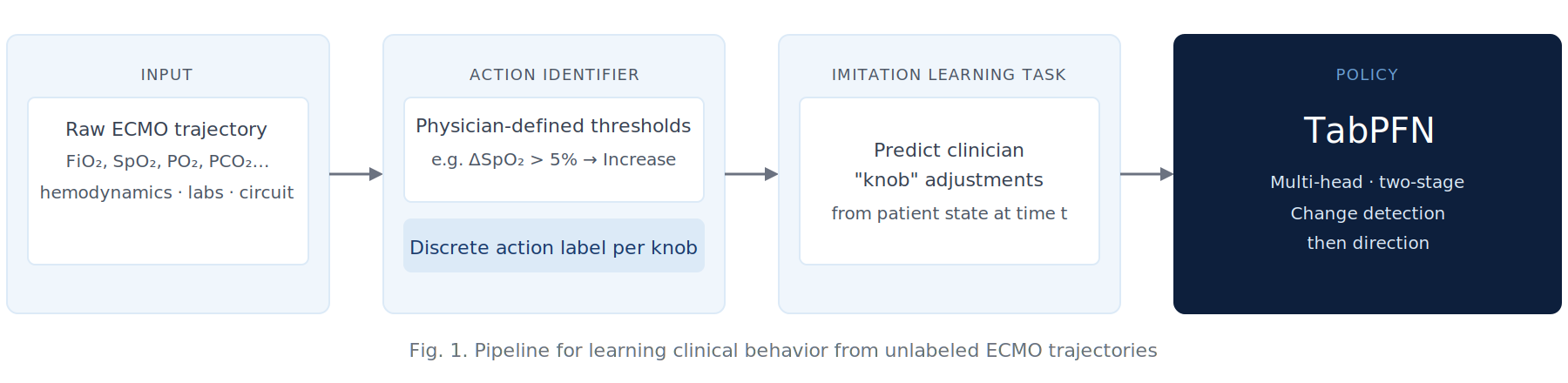
Fig. 1. Pipeline for learning clinical behavior from unlabeled ECMO trajectories. Raw physiologic telemetry is processed into discrete action labels using physician-defined thresholds. These discovered actions formulate an imitation learning task: predicting clinician "knob" adjustments from patient state.
Actionable features (knobs)
A discrete action is identified when the absolute change within a 60-minute window exceeds the specified threshold.
| Knob | Threshold | Action space |
|---|---|---|
| Arterial PO₂ | 25 mmHg | Increase / Same / Decrease |
| Arterial PCO₂ | 5 mmHg | Increase / Same / Decrease |
| SpO₂ | 5 % | Increase / Same / Decrease |
| FiO₂ | 10 % | Increase / Same / Decrease |
Pediatric ECMO cohort
78 pediatric ECMO trajectories obtained from Children’s Medical Center, Dallas. Cases with congenital heart disease were excluded due to the complexity of specialized management.
| Metric | Value |
|---|---|
| Patient trajectories | 78 |
| Average patient age | 4.66 years |
| Average trajectory length | 215 hours |
| State features per hour | 48 (23 clinical variables + deltas + ECMO type + on-ECMO indicator) |
| Actionable knobs | 4 (PO₂, PCO₂, SpO₂, FiO₂) |
| Source | Children's Medical Center, Dallas |
| Exclusion criterion | Congenital Heart Disease cases |
State features
For each variable, we include the mean value within a 60-minute window and its delta relative to the previous window. Heart rate (HR) and mean arterial pressure (ARTm) are age-normalized.
| Category | Features |
|---|---|
| Hemodynamics | Mean Arterial Pressure (ARTm), Heart Rate (HR), SpO₂, Cerebral Oximetry (rSO₂-1, rSO₂-2) |
| ECMO Circuit | Blood Flow (mL/kg/min), Sweep Gas CO₂ Flow, Sweep Gas O₂ Flow, FiO₂ – ECMO, Volume Sensor |
| Ventilator | Mean Airway Pressure (PAW), PEEP, Oxygen Concentration (FiO₂), Tidal Volume, End-tidal CO₂ (etCO₂) |
| Laboratory | Arterial PO₂, PCO₂, pH, Base Excess, Lactate, Ionized Calcium, Total CO₂, INR |
Evaluation across three questions
We evaluate generalization performance, calibration, and alignment with clinician decisions using leave-one-out (LOO) cross-validation. Given the inherent class imbalance, we quantify performance using balanced accuracy and macro-F1 scores for each action head.
Q1: Do policies generalize?
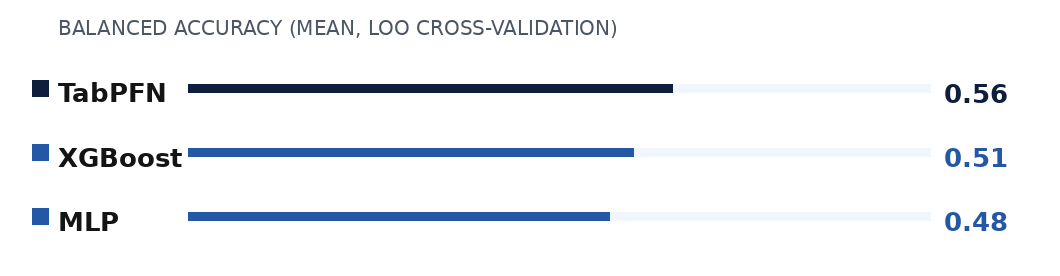
TabPFN achieves the highest mean balanced accuracy across the majority of the actions. The consistent improvement in balanced accuracy suggests that TabPFN is more resilient to the class imbalance inherent to this setting and generalizes more effectively to held-out patients. Ranking consistent across all four action knobs: PO₂, PCO₂, SpO₂, FiO₂.
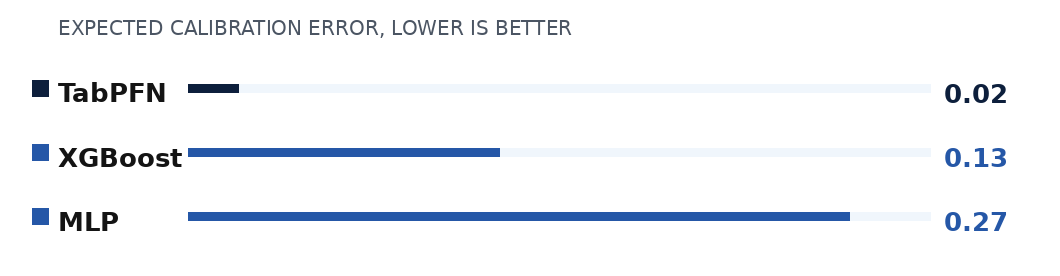
Q2: Are policies calibrated?
Expected Calibration Error (ECE) summarizes the average gap between a model’s stated confidence and its observed accuracy across probability bins. Lower ECE indicates more reliable estimates of uncertainty. TabPFN consistently achieves a lower ECE than the MLP and XGBoost baselines. The posterior probabilities produced by TabPFN’s in-context inference closely match its empirical accuracy, providing reliable confidence estimates.
Q3: Where do policies disagree with clinicians?
We identify regions of the state space with the highest model-expert disagreement by training shallow decision trees on the residual errors of their predicted probabilities. The table shows the most frequent features appearing in high-disagreement states, reported as the number of times each feature was selected across all knobs.
| Feature | MLP | TabPFN | XGBoost |
|---|---|---|---|
| FiO₂ | 2 | 5 | 5 |
| SpO₂ | 1 | 5 | 3 |
| pH | 2 | 3 | 2 |
| PO₂ | 3 | 2 | 1 |
| PCO₂ | 2 | 3 | 1 |
| Lactate | 3 | 1 | 1 |
Oxygenation-related signals, specifically FiO₂ and SpO₂, consistently define the boundaries where model predictions deviate from clinician actions. The models deviate from clinician actions in different regions of the state space, motivating future expert review of high-disagreement states.
Conclusion
We presented an imitation learning framework to model clinical decision-making in pediatric ECMO. Our framework maps patient states to concurrent clinical interventions by inferring action labels from patient trajectories and employing a factorized, hierarchical policy architecture.
Our empirical evaluation finds that TabPFN consistently outperforms traditional gradient-based baselines, suggesting that it can serve as an effective clinician-behavior baseline in challenging critical care settings. TabPFN encodes a broad tabular prior from its extensive pretraining on millions of synthetic datasets, enabling probabilistic inference in a single forward pass without requiring dataset-specific gradient-based training or hyperparameter tuning.
Future work
- Analyze whether model-clinician disagreements correlate with patient outcomes, such as risk of neurological injury.
- Explore policy improvement by incorporating expert-defined rewards.
- Perform a systematic analysis on the high-disagreement extracted rules and use them to elicit expert feedback for policy refinement.
Citation
If you build on or use portions of this work, please cite:
@inproceedings{golivand2026ecmo,
title = {Imitation Learning for Clinical Decision Support in Pediatric {ECMO}},
author = {Golivand Darvishvand, Fateme and Skinner, Michael and Mathur, Saurabh
and Soni, Ameet and Reeder, Phillip and Kersting, Kristian
and Raman, Lakshmi and Natarajan, Sriraam},
booktitle = {Proceedings of the 24th International Conference on
Artificial Intelligence in Medicine (AIME)},
year = {2026},
note = {Supported by NIH award R01NS133142}
}
Acknowledgements
We gratefully acknowledge the support of NIH award R01NS133142.